Extract text from document
Extracts text from images or pdf files. We can mark the regions to be extracted or extract the whole document.
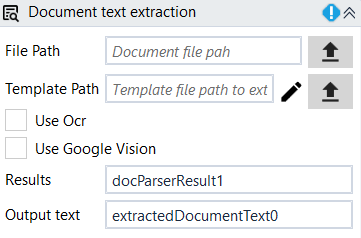
Designer Properties#
- File Path Path to the image or pdf file to extract text from.
- Template Path Path to the template file used for defining the regions inside the document for extraction. Usually, this is file is autogenerated using the template editor which can be started by pressing the pencil button.
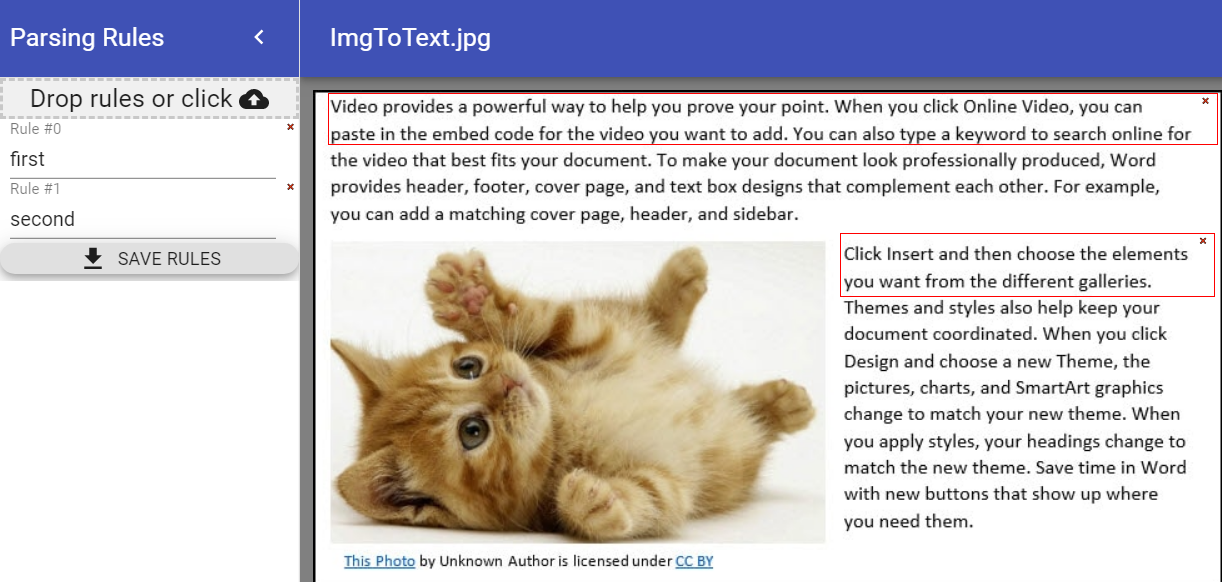 When pressing the edit template button with a file already set for "File Path", the above dialog will be displayed. To create a new rule just select a new region in the document. The selected region can be dragged or resized by just going with the mouse over it. Once saved, it can be used to extract similar documents. If there is no selection then we will extract all the content of the document.
When pressing the edit template button with a file already set for "File Path", the above dialog will be displayed. To create a new rule just select a new region in the document. The selected region can be dragged or resized by just going with the mouse over it. Once saved, it can be used to extract similar documents. If there is no selection then we will extract all the content of the document. - Use Ocr Use OCR for text extraction from images or pdf. The OCR used is Tesseract.
- Use Google Vision Uses Google Vision for Image to text. Tesseract is very good in most of the cases, but sometimes it may miss some details, and we may want to Google Vision.
- Results The extracted regions as a Dictionary(string, string) where Key is the name of the region given in the Template Editor for the rule, and the value is the extracted text for that rule.
- Output text The extracted text from the image or PDf file. If no rule is defined then it will be the content of the file as text, otherwise it will be the text from each region separated by new line.
Properties#
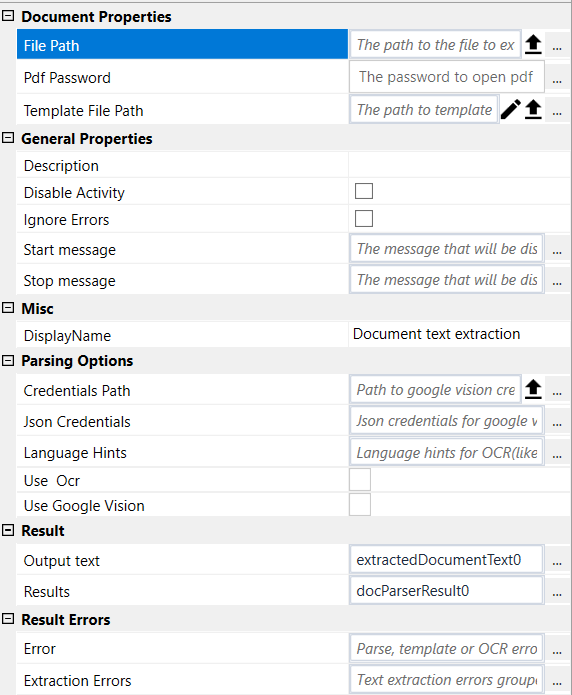
Document Properties#
See Designer Properties above.
General Properties#
See General Properties.
Misc#
See Misc.
Out Error#
See Out Error.
Parsing Options#
- Credentials Path Path to google credentials file for Google Vision OCR.
- Json Credentials Json credentials for Google Vision OCR as text. We just need to paste the Vision OCR json credentials content as a text under "".
- Language Hints Language Hints for Tesseract or Google Vision. For Tesseract, please check the following url https://github.com/tesseract-ocr/tessdata/. The language hint is the prefix of the file before dot. For instance, for Russian, the file is rus.traineddata, and the language hint is "rus". The same for Italian, the file is ita.traineddata and hint is "ita". For Google Vision, just the language code. For instance, For German is deu. We can even use multiple languages like "eng+deu".
- Use Ocr See Designer Properties above.
- Use Google Vision See Designer Properties above.
Result#
- Output text See Designer Properties above.
- Results The extracted regions as a Dictionary(string, string) where Key is the name of the region given in the Templa Editor for the rule, and the value is the extracted text for that rule.
Result Errors#
- Extraction Errors All the errors by rule represented as a Dictionary(string, string) where key is the name of the rule while value is the error reported while trying to extract the content for that rule(region represented by that rule).
- Parse Error Document parse error, if any.
Example#
Extract two regions from an image
In this example, we select two regions from the above image and extract the corresponding text. Once the text is extracted, we display a MessageBox with all the extracted text and 2 other MessageBoxes with the text extracted for the first and second region.