Extract table PDF
Extract tables and regions from pdf files. When extracting tables from Pdf files, we need to mark the column regions in the file and define the stop position of the extraction. If the stop position is not defined, the activity tries to extract the whole content of the file as table. For marking a table, just draw a rectangle over the column header and make sure that the rectangle covers the whole length of the column. The name of the rule should be as follows:myTable_ColumnName. E.g t1_Name where 't1' is the name of the table to be extracted and 'Name' is the name of the column to be written in the table. To mark the end of a table just draw a rectangle where the extraction should stop and name the rule as follows: myTable_footer. E.g t1_footer. You can extract individual regions by marking the region with a rectangle and providing a name for it. Individual regions are exported per page or for the whole document.
note
The DataTable column header is built from the selection and it has as the last column the page number.
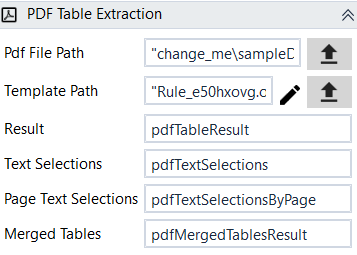
Designer Properties#
- Pdf File Path Path to the image or pdf file to extract text from.
- Template Path Path to the template file used for defining the regions inside the pdf file for extraction. Usually, this is file is autogenerated using the template editor which can be started by pressing the pencil button.
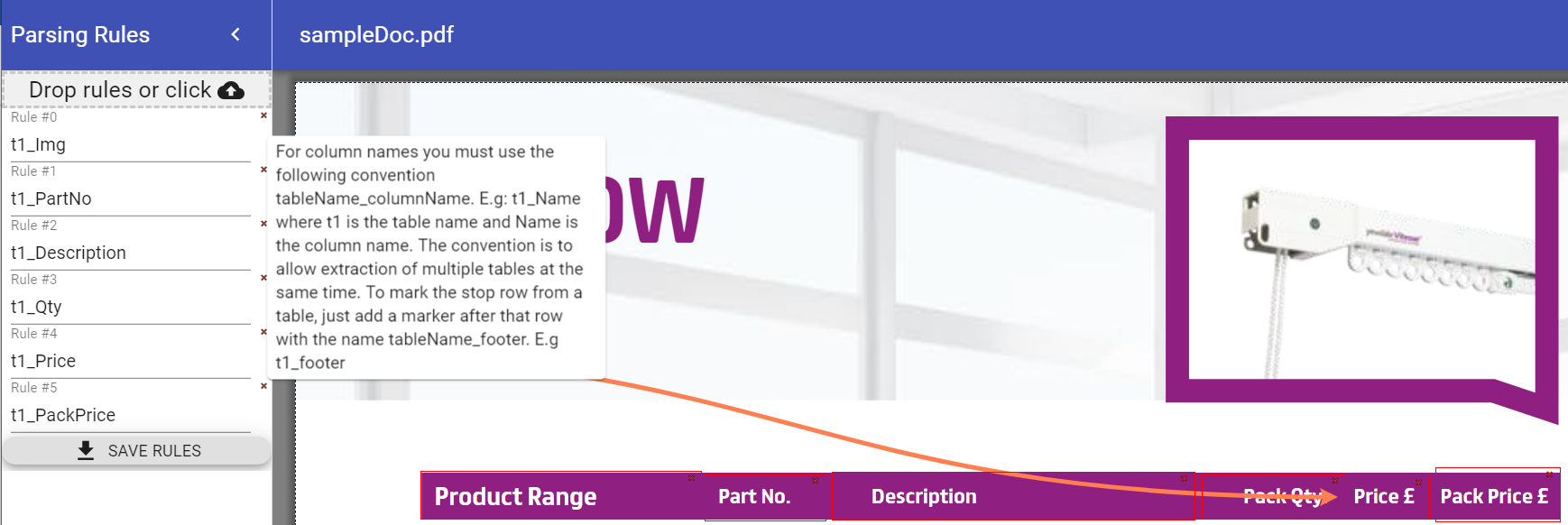 When pressing the edit template button with a file already set for "File Path", the above dialog will be displayed. For marking a table, just draw a rectangle over the column header and make sure that the rectangle covers the whole length of the column. The name of the rule should be as follows:myTable_ColumnName. E.g t1_Name where 't1' is the name of the table to be extracted and 'Name' is the name of the column to be written in the table. To mark the end of a table just draw a rectangle where the extraction should stop and name the rule as follows: myTable_footer. E.g t1_footer. You can extract individual regions by marking the region with a rectangle and providing a name for it. Individual regions are exported per page or for the whole document.
When pressing the edit template button with a file already set for "File Path", the above dialog will be displayed. For marking a table, just draw a rectangle over the column header and make sure that the rectangle covers the whole length of the column. The name of the rule should be as follows:myTable_ColumnName. E.g t1_Name where 't1' is the name of the table to be extracted and 'Name' is the name of the column to be written in the table. To mark the end of a table just draw a rectangle where the extraction should stop and name the rule as follows: myTable_footer. E.g t1_footer. You can extract individual regions by marking the region with a rectangle and providing a name for it. Individual regions are exported per page or for the whole document. - Result Resulting datatables after running the activity represented as a Dictionary(string, DataTable) where key is the name given to the datatable when defining the rules(as in the details above, the chosen name was t1) while the value is the extracted DataTable.
- Text Selections All text selections extracted from pdf file and represented as a Dictionary(string, string) where key is the name of the rule(given when the rule was created in Template Editor) while value is the extracted text.
- Page Text Selections All text selections by page and represented as a Dictionary(Dictionary(string, string)) where first key is the page number(1,2..), second key is the name of the rule(given when the rule was created in Template Editor) while value is the extracted text.
- Merge Tables All the extracted DataTables merged under one DataTable. If we mark only one DataTable for extraction then this will be the extracted DataTable.
Properties#
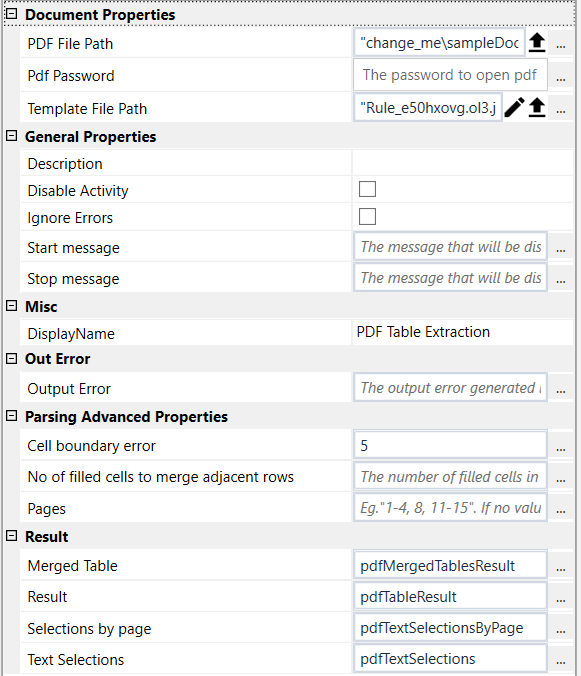
Document Properties#
- Pdf File Path See Designer Properties above.
- Pdf Password The pdf file password, if any.
- Template Path See Designer Properties above.
General Properties#
See General Properties.
Misc#
See Misc.
Out Error#
See Out Error.
Parsing Advanced Properties#
- Cell boundary error The bounding error in pixes user when determining the rows and cells.
- No of filled cells to merge adjacent rows The number of filled cells in a row to trigger a merge of adjacent rows with a distance less than 10 pixels.
- Pages The pages to be processed. Example "1-4, 8, 11-15". If no value is specified, the whole pdf will be processed
- Use Ocr Use OCR for text extraction from images or pdf. The OCR used is Tesseract.
- Use Google Vision Uses Google Vision for Image to text. Tesseract is very good in most of the cases, but sometimes it may miss some details, and we may want to Google Vision.
Result#
See Designer Properties above.
Example#
In this example, we extract from the attached pdf file the table from first and second page and display it in a DataTable editor.